前言
Envoy 是一款 CNCF 旗下的开源项目,由 Lyft 开源。Envoy 采用 C++ 实现,是面向 Service Mesh 的高性能网络代理服务。它与应用程序并行运行,通过以平台无关的方式提供通用功能来抽象网络。当基础架构中的所有服务流量都通过 Envoy 网格时,通过一致的可观测性,很容易地查看问题区域,调整整体性能。
Envoy 也是 Istio Service Mesh 中默认的 Data Plane,本文我们将讲解 Envoy 的一些基本概念,并采用一些实例来介绍如何在本地环境中快速使用 Envoy 作为 Service Mesh 的数据平面,以帮助读者理解 Istio 的 Data Panel 层实现。
更新历史
2021 年 03月 05日 - 初稿
扩展阅读
- https://holajiawei.com/envoy/
- https://www.lijiaocn.com/soft/envoy/
- https://www.jianshu.com/p/90f9ee98ce70
- https://github.com/wellls/blog/issues/47
- https://jimmysong.io/posts/envoy-as-front-proxy/
- https://www.yangcs.net/posts/run-envoy-on-your-laptop/
Envoy 特性
- 整体架构
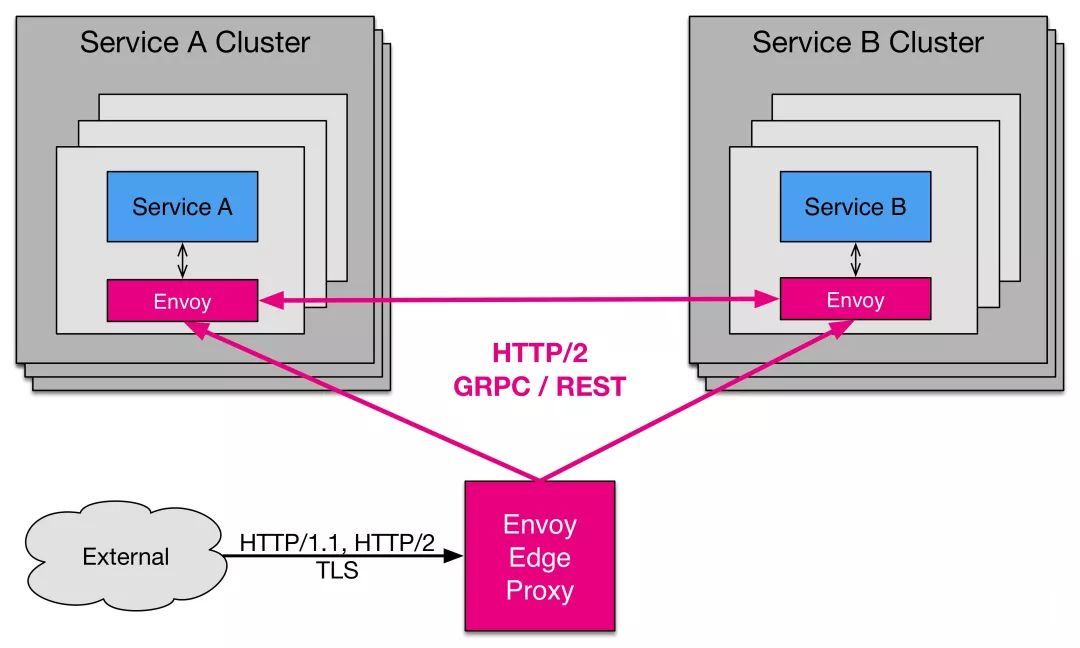
- 进程无关架构
Envoy 是一个自组织的模块,与应用 Server 并无直接依赖。所有的 Envoy 构建了一个透明的服务网格 Service Mesh,处于其中的应用只需要简单的与本地的 Envoy 进行收发信息,并不需要关注整个网络拓扑。这种架构对于应用通信有两大好处:
Envoy可以让任何的编程语言编写的服务通信,协同工作,Envoy帮你屏蔽了服务之间的沟壑。- 任何曾经在大型微服务开发中工作过的人都知道发布一个库更新是多么的痛苦。
Envoy可以以一种透明的方式快速的发布更新整个基础架构中的版本。
- 高级负载均衡
分布式系统中不同模块间的负载均衡是一个复杂的问题。因为 Envoy 是一个自组织的代理,所以它能在一个地方实现高级负载均衡技术并使他们可被访问。当前 Envoy 支持自动重试、断路器、全局限速、阻隔请求、异常检测,将来还会支持按计划进行请求速率控制。
- 动态配置
Envoy 提供了可选的一系列的分层的动态配置 API,使用这些 API 可以构建出复杂的集中式部署管理。
- 正向代理支持
虽然 Envoy 设计初衷是服务和服务之间通信系统,得益于其监视、管理、服务发现和负载均衡算法的实现,Enovy 包含了足够多的特性为绝大多数 Web 服务做正向代理。
除了这些之外还有对 HTTP/2 的支持,L3、L4、L7 代理,可以实现 TCP Proxy、HTTP Proxy 等功能。
- 线程模型
Envoy 使用单进程多线程架构,其中一个扮演主线程的控制各种协调任务,而一些工作线程负责监听、过滤和转发。一旦某个链接被监听器 Listener 接受,那么这个链接将会剩余的生命周期绑定在这个 Woker 线程。这种架构会使得大部分工作工作在单线程的情况下,只有少量的工作会涉及到线程间通信,Envoy 代码是 100% 非阻塞的。
- Listener 监听器
- 一个
Envoy进程可以设置多个不同的Listener,建议一台机器只使用一个Envoy实例。 - 每一个
Listener的网络层L3/L4过滤器是独立配置的。并且一个Listener是可以通过配置来完成多种任务的,比如:访问限制、TLS 客户端校验、HTTP 链接管理等。 Listener也有自己的非网络层过滤器,它可以修改链接的Metadata信息,通常用来影响接下来链接是如何被网络层过滤器处理的。- 无论网络层过滤器还是
Listener过滤器都可以提前终止后续的过滤器链的执行。
- HTTP 连接管理器
Envoy是完整支持HTTP/1.1、Websockets和HTTP/2,不支持SPDY。- 这层过滤器主要是将原始的传递数据转变成
HTTP层级的信息和事件,如收到Headers、收到Body数据,同样它也可以做接入日志、Request ID生成和追踪、Req/Res头部修改工作、路由表管理、统计分析。 - 每一个
HTTP链接管理器有一个相匹配的路由表,路由表可以静态指定,也可以动态地通过RDS API来设置route-dynamic。 - 其内部还有
HTTP过滤器,可以支持在HTTP层级。在无需关注使用什么协议 (HTTP/1.1或HTTP/2) 实现的情况下进行操作HTTP内容,支持Encode、Decode、Encode/Decode三种不同类型过滤器。
- HTTP 路由器
- 经常用在做边缘/反向代理和构建内部
Envoy Mesh发挥巨大作用。 HTTP路由器可以支持请求重试配置:最大重试次数和设置重试条件,比如某些5XX错误和具有幂等性操作的4XX错误。Envoy自己使用HTTP/2链接管理器实现了gRPC协议,将原来官方的Google gRPC内置的很多功能,比如重试、超时、Endpoint发现、负载均衡、负载报告、健康检查等功能都实现了。将来除非特殊特性必须,都可以使用Envoy gRPC来实现。
- Cluster 管理器
Cluster 管理器暴露 API 给过滤器,并允许过滤器可以得到链接到上游集群的 L3/L4 链接或者维持一个抽象的 HTTP 连接池用来链接上游集群(上游主机支持 HTTP 1.1 还是 HTTP 2 都是被隐藏的)。过滤器决定是使用 L3/L4 链接还是 HTTP Stream 来链接上游集群。而对于集群管理器来说,它负责所有集群内主机的可用性、负载均衡、健康度、线程安全的上游链接数据,上游链接类型 TCP/UP、UDS,上游可接受的协议 HTTP 1.1/2。
Cluster 管理器既可以静态配置,也可以使用 CDS-Cluster-Discovery-Service API 来动态配置。 集群在正式使用之前有一个 “加热” Warming 的过程:先做服务发现必要的初始化,比如 DNS 记录更新、EDS 更新,然后进行健康检查,当进行完上述的过程,会进入Becoming available 状态,这个阶段 Envoy 不会把流量指向它们; 在更新集群时,也不会把正在处理流量的集群处理掉,而是用新的去替换老的那些还未进行任何流量的集群。
- 与 Nginx 的区别
Envoy对HTTP/2的支持比Nginx更好,支持包括upstream和downstream在内的双向通信,而Nginx只支持downstream的连接。- 高级负载均衡功能是免费的,
Nginx的高级负载均衡功能则需要付费的Nginx Plus支持。 Envoy支持热更新,Nginx配置更新之后需要Reload。Envoy更贴近Service Mesh的使用习惯,Nginx更贴近传统服务的使用习惯。
Envoy 术语
要深入理解 Envoy,首先需要先了解一下 Envoy 中的一些术语。
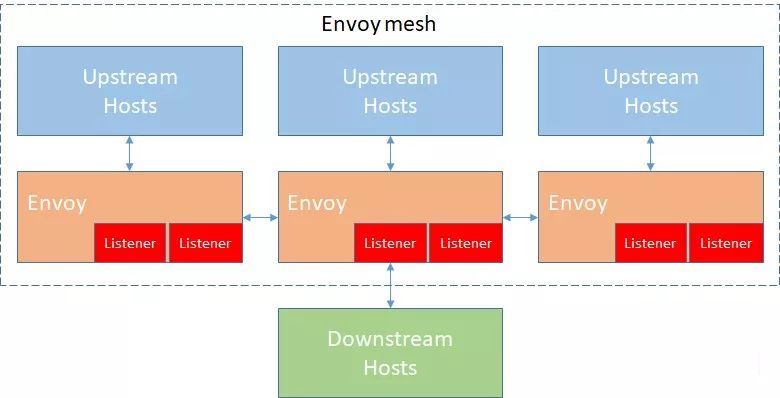
Host:能够进行网络通信的实体(如服务器上的应用程序)。Downstream:下游主机连接到Envoy,发送请求并接收响应。Upstream:上游主机接收来自Envoy连接和请求并返回响应。Listener:可以被下游客户端连接的命名网络(如端口、Unix套接字)。一般是每台主机运行一个Envoy,使用单进程运行,但是每个进程中可以启动任意数量的Listener(监听器),每个监听器都独立配置一定数量的(L3/L4)网络过滤器。Cluster:Envoy连接到的一组逻辑上相似的上游主机。Mesh:以提供一致的网络拓扑的一组主机。Runtime Configuration:与Envoy一起部署的外置实时配置系统。Listener Filter:Listener使用Listener Filter(监听器过滤器)来操作链接的元数据,它的作用是在不更改Envoy的核心功能的情况下添加更多的集成功能。Http Route Table:HTTP的路由规则,例如请求的域名,Path符合什么规则,转发给哪个Cluster。
部署 Envoy
官方提供了 Envoy 的 Docker 镜像,直接下载对应镜像即可使用。
1 | $ docker pull envoyproxy/envoy:latest |
镜像中已经将 Envoy 安装到 /usr/local/bin 目录下,可以先看看 Envoy 进程的帮助信息。
1 | # /usr/local/bin/envoy --help |
Envoy 进程启动的时候需要指定一些参数,其中最重要的是 --config-yaml 参数,用于指定 Envoy 进程启动的时候需要读取的配置文件地址。Docker 中配置文件默认是放在 /etc/envoy 目录下,配置文件的文件名是 envoy.yaml。所以我们在启动容器的时候需要将自定义的 envoy.yaml 配置文件挂载到指定目录下替换掉默认的配置文件。
1 | # /usr/local/bin/envoy -c <path to config>.{json,yaml,pb,pb_text} --v2-config-only |
注意:
Envoy默认的日志级别是info,对于开发阶段需要进行调试的话,调整日志级别到Debug是非常有用的。你可以在启动参数中添加-l debug来将日志级别进行切换。
编写 Envoy 配置文件
在介绍 Envoy 的配置文件之前,先介绍一下 Envoy 的 API。Envoy 提供了两个版本的 API,V1 和 V2 版本 API。现阶段 V1 版本已经不建议使用了,通常都是使用 V2 的 API。
V2 的 API 提供了两种方式的访问,一种是 HTTP Rest 的方式访问,还有一种 GRPC 的访问方式。关于 GRPC 的介绍可以参考官方文档,在后面的文章中只实现了 GRPC 的 API。
Envoy 的启动配置文件分为两种方式:静态配置和动态配置。
静态配置是将所有信息都放在配置文件中,启动的时候直接加载。
动态配置需要提供一个 Envoy 的服务端,用于动态生成 Envoy 需要的服务发现接口,这里叫 XDS ,通过发现服务来动态的调整配置信息,Istio 就是实现了 V2 的 API。
静态配置
以一个最简化的静态配置来做示例,体验一下 Envoy。
下面是 envoy.yaml配置文件:
1 | admin: |
在此基础上启动两个容器,envoyproxy 容器和 nginx 容器,nginx 容器共享 envoyproxy 容器的网络,以此来模拟 Sidecar。
1 | $ docker run -d -p 10000:10000 -v `pwd`/envoy.yaml:/etc/envoy/envoy.yaml --name envoyproxy envoyproxy/envoy:latest |
根据配置文件的规则,Envoy 监听在 10000 端口,同时该端口也在宿主机的 10000 端口上暴露出来。当有请求到达监听上后,Envoy 会对所有请求路由到 some_service 这个 Cluster 上,而该 Cluster 的 Upstream 指向本地的 80 端口,也就是 Nginx 服务上。
动态配置
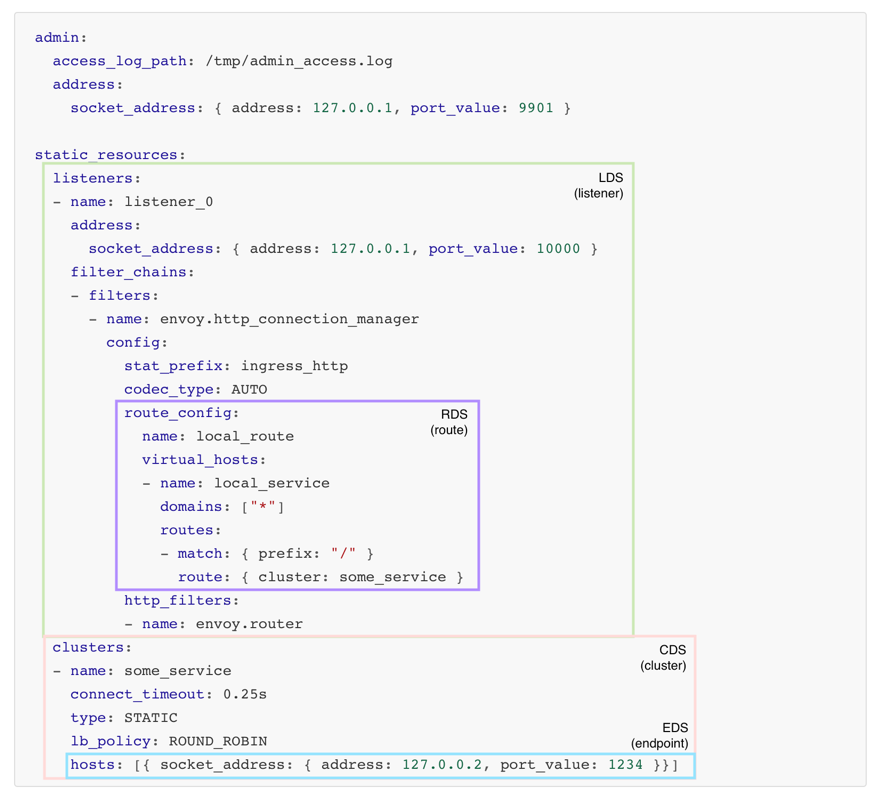
动态配置可以实现全动态,即实现 LDS (Listener Discovery Service)、CDS (Cluster Discovery Service)、RDS (Route Discovery Service)、EDS (Endpoint Discovery Service),以及 ADS (Aggregated Discovery Service)。
ADS 不是一个实际意义上的 XDS,它提供了一个汇聚的功能,以实现需要多个同步 XDS 访问的时候可以在一个 Stream 中完成的作用。
下面的图通过在静态配置的基础上,比较直观的表示出各个发现服务所提供的信息。
由此,典型的动态配置文件如下:
1 | admin: |
注意:动态配置和静态配置最大的区别在于,启动的时候一定要指定
cluster和id,这两个参数表示该 Envoy 进程属于哪个Cluster,id要求在相同的Cluster下唯一,以表示不同的指向发现服务的连接信息。这两个参数可以在Envoy的启动命令中添加--service-cluster和--service-node来指定,也可以在envoy.yaml配置文件中指定node.cluster和node.id。
Envoy 使用实例
入门实例
了解一个开源软件,从官方实例入手再好不过了,因此下面的例子将会围绕官方仓库中的实例展开。所以在开始之前,你需要安装并配置以下工具:
DockerDocker ComposeGitCurl
我们将会使用 Docker 和 Docker Compose 来构建和运行几个 Envoy 示例服务,并用 Curl 来检测 Envoy 示例服务是否在运行。
运行 Envoy
首先克隆 Envoy 官方仓库到本地,并定位到 envoy/examples/front-proxy 文件夹。
1 | $ git clone https://github.com/envoyproxy/envoy |
front-proxy 文件夹中的服务是一个用 Flask 实现的后端服务,入口文件在 service.py 文件里面。Envoy 作为一个 Sidecar 部件,将与 service.py 在同一个容器中运行,并由 docker-compose,.yaml 文件配置。
前端代理比后端服务更简单,它使用配置文件 front-envoy.yaml 来运行 Envoy。Dockerfile-frontenvoy 文件则是 front-envoy 的 Dockerfile。
如果你之前没有接触过 Docker 的话,你可以使用以下命令在本地构建并运行 front-proxy 的 Docker 镜像:
1 | $ cd /path/to/envoy/examples/front-proxy |
其中的 --build 表示构建镜像, -d 表示在后台运行所有 docker-compose 配置文件中定义的镜像,具体可参考 Docker 相关文档。
命令运行成功后,将会启动一个前端代理和两个服务实例:service1 和 service2。你可以通过以下命令来验证容器是否正常运行:
1 | $ docker-compose ps |
正常的话会返回以下内容:
1 | $ front-proxy git:(master) docker-compose ps |
测试服务是否连通
你可以使用 curl 或者浏览器来测试服务是否在正常运行
浏览器中输入 http://localhost:8000/service/1 或者使用以下命令:
1 | $ curl http://localhost:8000/service/1 |
如果返回结果是像下面这样,则表示 service1 的 Envoy 服务正常运行:
1 | Hello from behind Envoy (service 1)! hostname: a841ffceafd0 resolvedhostname: 172.18.0.4 |
你也可以用同样的方法测试 service 2 的服务。
1 | $ curl http://localhost:8000/service/2 |
返回的结果和 service 1 类似。
1 | Hello from behind Envoy (service 2)! hostname: e83b35c6f4fe resolvedhostname: 172.18.0.3 。 |
Envoy 配置
下面我们先简单看一下 Envoy 的静态配置信息,之后再继续看 Demo 中的动态配置信息。
我们先从 front-envoy.yml 入手。打开文件之后,我们会发现这个 yaml 有两个最高的层级,分别是 static_resources 和 admin 。admin 的内容相对比较简单,总共只有六行:
1 | admin: |
其中 access_log_path 字段值是 /dev/null,其含义是 admin 服务的请求日志将不会被保存。生产环境中可自行将目标目录指定到需要的地方。address 和 port_value 字段分别表示 admin server 运行的 IP 端口。
static_resource 的内容定义了非动态管理的集群(Cluster)和监听器(Listener)相关配置。集群是 Envoy 连接到的一组逻辑上相似的上游主机,一个集群是一组被定义的 ip/port 集合,Envoy 将借此实现负载均衡。监听器是一组被定义的网络地址,它是可以由下游客户端连接的命名网络位置(例如,端口、Unix 域套接字等)。监听器是服务(程序)监听者,就是真正干活的,客户端可借此连接至服务。
front proxy 中只有一个监听器,监听器中除了 socket_address 之外还有一个字段是 filter_chains,Envoy 通过此字段来管理 HTTP 的连接和过滤。
1 | listeners: |
其中有个配置选项是 virtual_hosts,该选项在 HTTP 连接管理过滤器中用作定义虚拟主机,并通过正则过滤允许访问服务的域名。路由也在其中配置,例子中将 /service/1 和 /service/2 的请求分别转发到了其相应的集群中。
1 | virtual_hosts: |
接下来我们继续看静态集群的配置:
1 | clusters: |
在静态集群的配置内容中,我们可以配置超时时间、熔断器、服务发现等等内容。集群由一系列端点 (Endpoints) 组成,端点就是一组服务集群中可以响应访问请求的网络地址。在上面的例子中,端点标准定义成 DNS ,除此之外,端点可以直接被定义成 Socket 地址,或者是可动态读取的服务发现机制。
尝试动手修改配置
我们可以在本地尝试自己修改配置,重建镜像,测试修改后的配置。监听过滤器是 Envoy 为监听器提供的附加功能。比方说,想要增加访问日志到我们的 HTTP 过滤器中,只要增加 access_log 字段到配置文件中即可:
1 | - filters: |
修改之后,先通过 docker-compose down 命令关闭 docker-compose 容器组,然后使用 docker-compose up --build -d 命令重新构建镜像并运行容器组即可。
为了验证我们新增的 access_log 字段是否生效,我们可以模拟几次请求。然后通过命令 docker-compose exec front-envoy /bin/bash 手动进入容器内部查看访问日志是否在相应的目录中,你会看到 /var/log/access.log 文件记录着你的请求结果。
管理页面
Envoy 的一大特色是内置了管理页面,你可以通过 http://localhost:8001 访问。管理页面中 /cluster 菜单展示了上游 (Upstream) 集群端口的统计内容,stats 菜单则显示了更多端口的统计内容。
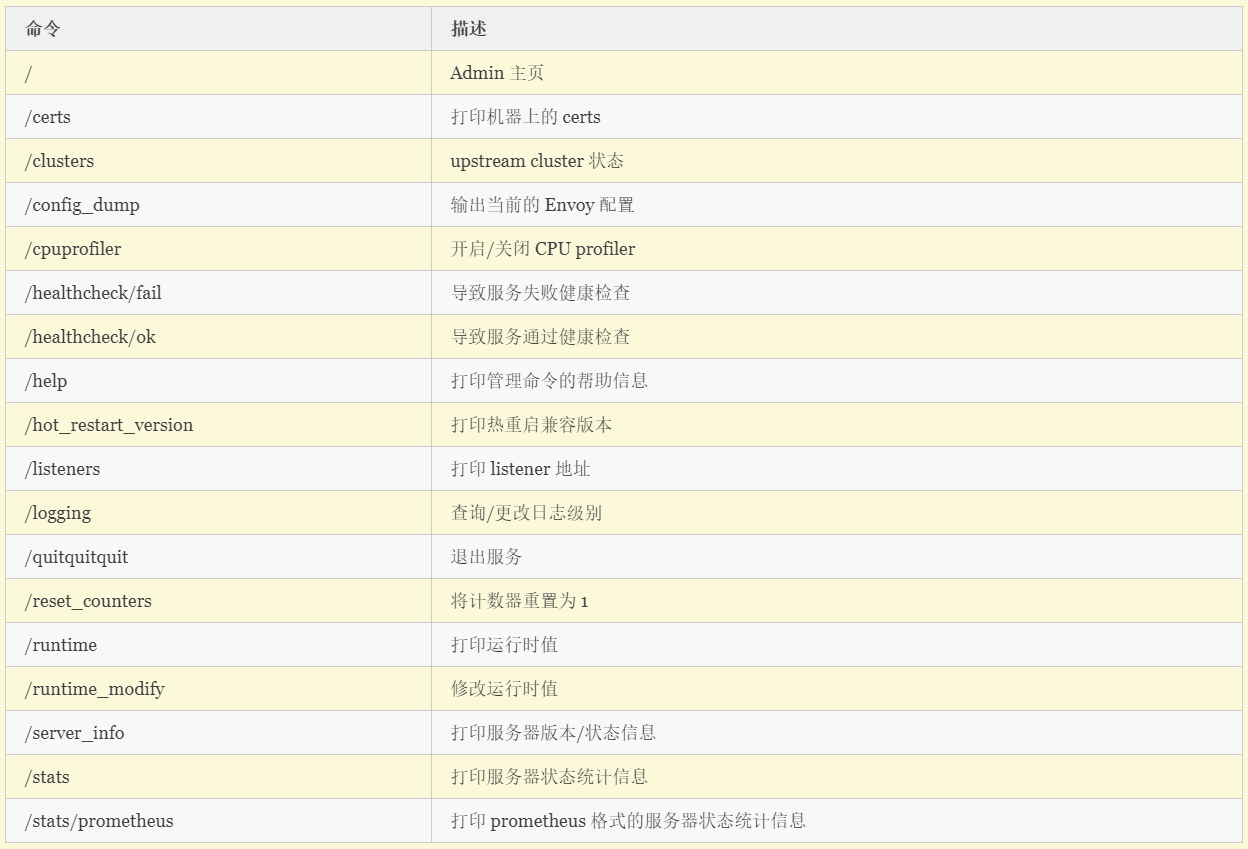
更多管理页面的内容你可以直接访问帮助页面 http://localhost:8001/help 来查看。
请求处理流程
Envoy 中对访问请求的处理流程大致如下,先将请求数据预处理,转成 Envoy 中的 Filter, 读写请求的 filter 分别是 ReadFilter 和 WriteFiler,对每个网络层也有各自的 filter ,TCP 的是 TcpProxyFilter, HTTP 的是 ConnectionManager,都由读 filter ReadFilter 继承而来。各个 filter 预处理完成之后就会组织成上面示例配置文件中有提到的 FilterChain, 收到 FilterChain 之后会将其路由到指定的集群中,并根据负载均衡获取到相应的地址,然后将请求转发出去。
进阶实例
接下来的实验主要以动态配置的方式来实现一个简单的需求,首先描述一下需求场景:有两个微服务,一个是 envoy-web,一个 envoy-server。
envoy-web相当于下图中的front-envoy作为对外访问的入口。envoy-server相当于下图中的service_1和service_2,是内部的一个微服务,部署2个实例。

envoy-server 有 3 个 API,分别是 /envoy-server/hello、/envoy-server/hi、/envoy-server/self,目的是测试 Envoy 对于流入 envoy-server 的流量控制,对外只允许访问 /envoy-server/hello 和 /envoy-server/hi 两个 API,/envoy-server/self 不对外暴露服务。
envoy-web 也有 3 个 API,分别是 /envoy-web/hello、/envoy-web/hi、/envoy-web/self,目的是测试 Envoy 对于流出 envoy-web 的流量控制,出口流量只允许 /envoy-web/hello 和 /envoy-web/self 两个访问出去。
最终的实验:外部只能访问 envoy-web 暴露的接口
- 当访问
/envoy-web/hello接口时返回envoy-server的/hello接口的数据,表示envoy-web作为客户端访问envoy-server返回服务响应的结果。 - 当访问
/envoy-web/hi接口时,envoy-web的envoy拦截住出口流量,限制envoy-web向envoy-server发送请求,对于前端用户返回mock数据。 - 当访问
/envoy-web/self接口时,envoy-web出口流量可以到达envoy-server容器,但是envoy-server在入口流量处控制住了此次请求,拒绝访问envoy-server服务,对于前端用户返回mock数据。
静态配置
首先,以静态配置的方式先实现功能。
编写服务代码
服务代码分为 envoy-web 和 envoy-server 两个服务,采用 SpringBoot 的方式,下面记录一些重要的代码片段。
- envoy-server
1 | @RestController |
- envoy-web
1 | @RestController |
注:为简化起见,代码只是介绍对出入流量的控制,直接在
envoy-web上访问了本地的Envoy端口进行转发流量,实际代码中可以用服务名:服务端口号访问,而此时为了使得Envoy仍然可以拦截入和出的流量,可以配置Iptables(Istio的实现中也是使用了Iptables)。
编写配置文件
针对不同的服务,也配置了两份 envoy.yaml 配置文件。
- envoy-server
1 | admin: |
- envoy-web
1 | admin: |
启动测试
1 | # envoy-server1 |
当容器部署完毕之后,可以直接访问以下 3 个 URL ,其中 hi 和 self 的访问返回的是 mock 数据,虽然同为 mock 数据,但是这两个 URL 其实是不相同的,一个是在 Envoy 出口流量处做的控制,一个是在 Envoy 入口流量处做的控制,其中的细节可以再去品味品味。

动态配置
动态配置需要实现发现服务,通过 GRPC 的方式获取相应。
动态的配置文件在前面的内容中已经有过介绍,最重要的是需要提供一个发现服务,对外提供 XDS 服务,下面以其中的一个 LDS 作为介绍,其他 XDS 实现类似。
服务端:既然作为服务,就需要对外提供接口服务。
1 | public class GrpcService { |
XDS 通过 GRPC 生成服务端的 stub 文件,实现 LdsServer 继承自 ListenerDiscoveryServiceGrpc.ListenerDiscoveryServiceImplBase,需要实现 streamListeners 方法。
1 | public class LdsService extends ListenerDiscoveryServiceGrpc.ListenerDiscoveryServiceImplBase { |
总结
至此,我们就基本介绍完 Envoy 使用的一些常见的使用方法,在实现的时候也会有其他一些细节需要注意。比如,Envoy 作为一个服务之间网络请求的代理,如何拦截全部的入和出流量?
Istio 给了一个很好的解决方案,就是通过 Iptables。它会使用一个特定的 uid(默认 1337)用户运行 Envoy 进程,Iptables 对于 1337 用户的流量不做拦截。下面就是参考 Istio 的 iptables.sh 做的一个实现:
1 | uname=envoy |